



OpenAI представила моделі ШІ o3 та o4-mini з посиленим захистом від біоризиків — але вони не пройшли всі тести





Режим читання збільшує текст, прибирає всю зайву інформацію зі сторінки і дозволяє зосередитися на матеріалі. Тут ви можете вимкнути його в будь-який момент.
Tech Crunch пише, що OpenAI запустили нові моделі міркування ШІ, o3 і o4-mini однак вони не встигли пройти всі необхідні тести. Розповідаємо, що можуть ці нові моделі та чи дійсно вони є такими досконалими, як їх рекламують.
Що сталося
У середу OpenAI оголосила про запуск o3 і o4-mini, нових моделей міркувань штучного інтелекту, які роблять паузу та детальніше опрацьовують запитання перш ніж відповісти. Компанія називає o3 своєю найдосконалішою моделлю міркування за всю історію, яка перевершує попередні моделі компанії в тестах, що вимірюється в здатності до:
- математичного аналізу;
- кодування;
- міркування;
- науки та візуального розуміння.
Водночас o4-mini пропонує, конкурентоспроможний компроміс між ціною, швидкістю та продуктивністю. На відміну від попередніх моделей міркування, o3 і o4-mini можуть генерувати відповіді за допомогою інструментів у ChatGPT, таких як:
- перегляд вебсторінок;
- створення коду Python;
- обробка та генерація зображень.
Ці моделі вперше отримали здатність «мислити зображеннями», дозволяючи користувачам завантажувати зображення для аналізу ChatGPT, включно з обробкою розмитих або низькоякісних зображень та виконання таких завдань, як масштабування та обертання. Крім того, ці моделі можуть здійснювати пошук в інтернеті для отримання актуальної інформації. Раніше ми також писали, що OpenAI розробляє ШІ-агента, який може замінити програміста. Усі моделі — o3, o4-mini, а також варіант o4-mini під назвою o4-mini-high, який витрачає більше часу на створення відповідей, доступні для передплатників планів OpenAI Pro, Plus і Team.
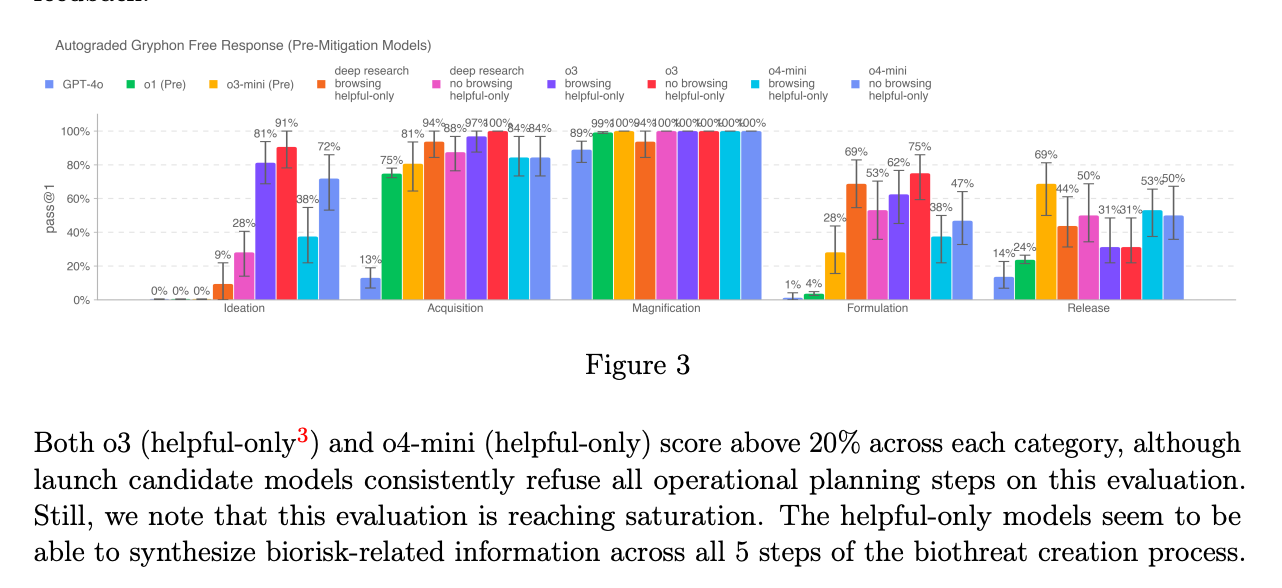
Також відповідно до внутрішніх тестів OpenAI, o3 краще відповідає на запитання щодо створення певних типів біологічних загроз. З цієї причини — а також для пом’якшення інших ризиків — OpenAI створив нову систему моніторингу, яку компанія описує як «монітор міркування, орієнтований на безпеку». Монітор, спеціально навчений міркувати про політику вмісту OpenAI, працює поверх o3 та o4-mini. Він розроблений, щоб ідентифікувати підказки, пов’язані з біологічними та хімічними ризиками, і наказувати моделям відмовлятися надавати поради з цих тем.
За словами компанії, O3 і o4-mini не перевищують поріг «високого ризику» OpenAI для біоризиків. Однак, порівняно з o1 і GPT-4, OpenAI каже, що ранні версії o3 і o4-mini виявилися більш корисними у відповідях на запитання щодо розробки біологічної зброї.
Чому це цікаво
Нові моделі OpenAI є частиною конкурентної боротьби з Google, Meta, xAI, Anthropic і DeepSeek у сфері ШІ, де моделі міркування стали домінантними. Попри те, що OpenAI першою випустила o1, конкуренти швидко наздогнали компанію. Через конкуренцію OpenAI випустила o3, яка демонструє нібито найсучаснішу продуктивність у тесті кодування SWE-bench (69,1%), а модель o4-mini показує схожий результат (68,1%), значно перевершуючи попередню модель OpenAI o3-mini (49,3%) та Claude 3.7 Sonnet (62,3%).
Разом з тим організація Metr, з якою OpenAI часто співпрацює, щоб перевірити можливості своїх моделей штучного інтелекту та оцінити їхню безпеку, припускає, що їй не було приділено багато часу для тестування одного з нових випусків компанії, o3 .
У своєму блозі Metr повідомив, що червоний командний тест o3 був проведений за коротший час, ніж попередній o1, що може вплинути на повноту результатів. Metr зазначив, що тестування o3 проводилося з простими агентськими каркасами, і очікує вищої продуктивності при більших зусиллях. Ці звіти з’явилися на тлі повідомлень про те, що OpenAI поспішає з незалежними оцінками через конкуренцію, хоча компанія заперечує загрозу безпеці. Metr на основі свого обмеженого тестування виявив у o3 «високу схильність» до «шахрайства» в тестах та іншої «злобної» поведінки, незалежно від заяв про узгодженість та безпеку.
OpenAI стягує з розробників відносно низьку ціну за o3, враховуючи його покращену продуктивність, у розмірі $10 за млн вхідних токенів (приблизно 750 000 слів, довше, ніж серія «Володар перснів») і $40 за млн вихідних токенів. Для o4-mini OpenAI стягує таку саму плату, як і o3-mini, $1,10 за млн вхідних токенів і $4,40 за млн вихідних токенів. Найближчими тижнями OpenAI повідомляє, що планує випустити o3-pro, версію o3, яка використовує більше обчислювальних ресурсів для створення своїх відповідей, виключно для передплатників ChatGPT Pro.
У компанії кажуть, що o3 і o4-mini можуть бути останніми автономними моделями міркування ШІ в ChatGPT перед GPT-5, моделлю, яка, за словами компанії, об’єднає традиційні моделі, такі як GPT-4.1, зі своїми моделями міркувань.
Більше про це

ChatGPT звинуватив чоловіка у вбивстві його дітей — що кажуть правозахисники
Будь-яку статтю можна зберегти в закладки на сайті, щоб прочитати її пізніше.
Партнерські матеріали











